
前言
本系列文章將透過系統介紹資料科學(Data Science)相關的知識,透過 Python 帶領讀者從零開始進入資料科學的世界。這邊我們將介紹 Numpy 這個強大的 Python 函式庫。
什麼是 Numpy?
Numpy 是 Python 的一個重要模組(Python 是一個高階語言也是一種膠水語言,可以透過整合其他低階語言同時擁有效能和高效率的開發),主要用於資料處理上。Numpy 底層以 C 和 Fortran 語言實作,所以能快速操作多重維度的陣列。當 Python 處理龐大資料時,其原生 list 效能表現並不理想(但可以動態存異質資料),而 Numpy 具備平行處理的能力,可以將操作動作一次套用在大型陣列上。此外 Python 其餘重量級的資料科學相關套件(例如:Pandas、SciPy、Scikit-learn 等)都幾乎是奠基在 Numpy 的基礎上。因此學會 Numpy 對於往後學習其他資料科學相關套件打好堅實的基礎。
Numpy 基礎操作
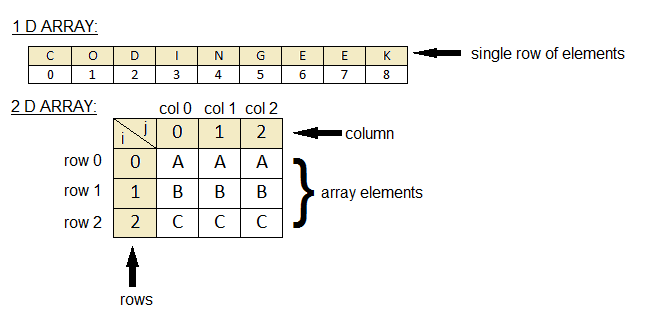
Numpy 陣列
Numpy 的重點在於陣列的操作,其所有功能特色都建築在同質且多重維度的ndarray(N-dimensional array)上。ndarray的關鍵屬性是維度(ndim)、形狀(shape)和數值類型(dtype)。 一般我們稱一維陣列為vector而二維陣列為matrix。一開始我們會引入numpy模組,透過傳入list到numpy.array()創建陣列。1
2
3
4
5
6
7
8
9
10
11
12# 引入 numpy 模組
import numpy as np
np1 = np.array([1, 2, 3])
np2 = np.array([3, 4, 5])
# 陣列相加
print(np1 + np2) # [4 6 8]
# 顯示相關資訊
print(np1.ndim, np1.shape, np1.dtype) # 1 (3,) int64 => 一維陣列, 三個元素, 資料型別
np3 = np.array([1, 2, 3, 4, 5, 6])從檔案取資料:
1
npd = np.genfromtxt('data.csv', delimiter=',')
改變陣列維度:
1
2np3 = np3.reshape([2, 3])
print(np3.ndim, np3.shape, np3.dtype) # 2 (2, 3) int64改變陣列型別(bool、int、float、string):
bool可以包含 True、False,int可以包含 int16、int32、int64。其中數字是指bits。float可以包含 16、32、64 表示小數點後幾位。string可以是 string、unicode。nan則表示遺失值。1
2
3np3 = np3.astype('int64')
np3.dtype
# dtype('int64')建立陣列
建立填滿 0 或 1 的陣列:1
2np1 = np.zeros([2, 3]) # array([[ 0., 0., 0.], [ 0., 0., 0.]])
np2 = np.ones([2, 3]) # array([[ 1., 1., 1.], [ 1., 1., 1.]])
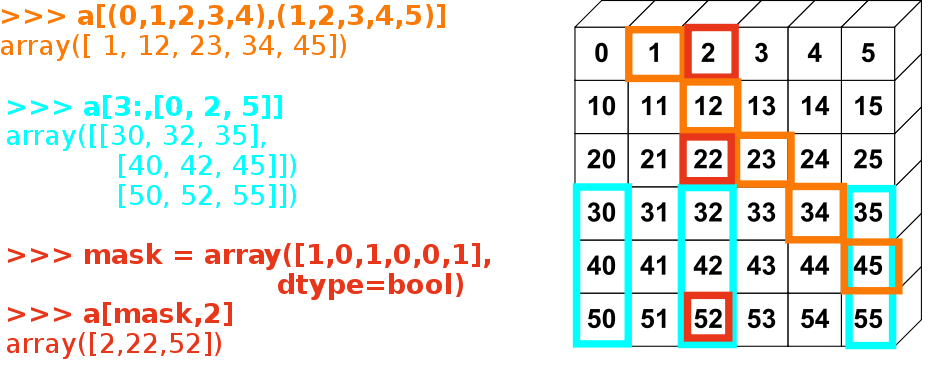
陣列索引與切片
一維陣列操作和 Python 原生 list 類似:1
2np3 = np.array([1, 2, 3, 4, 5, 6])
print(np3[2]) # 3二維陣列:
1
2
3np3 = np3.reshape([2, 3])
print(np3[1, 0]) # 4
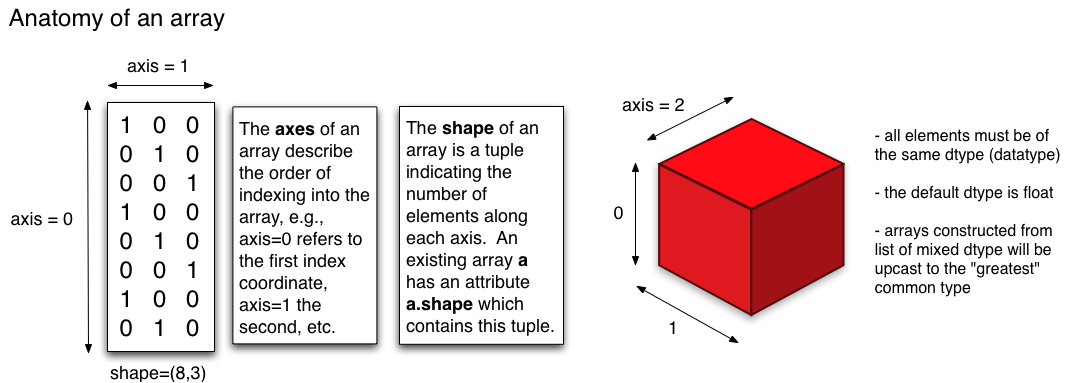
基本操作
使用布林遮罩來取值:1
2
3np3 = np.array([1, 2, 3, 4, 5, 6])
print(np3 > 3) # [False False False True True True]
print(np3[np3 > 3]) # [4 5 6]加總:
1
2np3 = np3.reshape([2, 3])
print(np3.sum(axis=1)) # 將 axis=1 橫向加總 [6 15]
總結
以上介紹了 Numpy 的基礎知識,建立了基本的 array 和 ndarray 的觀念。相信在熟悉 Numpy 之後 Pandas 的學習將會比較容易 (Pandas 的資料容器 DataFrame、Series 事實上是奠基在 Numpy 的陣列上)
延伸閱讀
(image via berkeley、codingeek、cornell、scipy-lectures)

